Visual Studio 2005(*1) で Visual Source Safe 6.0 (以下VSS6) を使用していると文字化けすることがあります。
たとえば時折、こんなダイアログが表示されたりします。
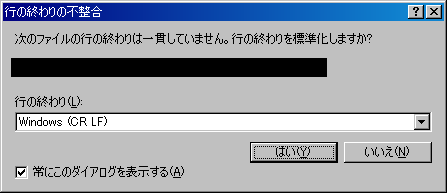
対策としては、以下のようなことが言われているようです。
- 文字化けが発生する行の行末を、漢字(=マルチバイト文字)ではなく、シングルバイト文字(=ASCII)にします。
- 具体的には、コメントなどで行末が漢字で終わる場合には、行の最後に必ずホワイトスペースを補うようにします。
この現象は、VSS6 が UTF-8 に対応していないことに起因します。
ある条件が成立したとき、VS6S はソースコードをチェックインするとき、行末の「0D-0A(CR-LF)」を「0D 0D-0A(CR CR-LF)」と CR を一つ余分に記録してしまいます。
メカニズムは以下のような感じです。
例えば以下の文字があるとします。
あいう[改行]
UTF-8 では以下のように記録されます。
E3-81-82 E3-81-84 E3-81-86 0D-0A
ところが VSS6 はこのバイト列を Shift-JIS だと思って処理します。
Shift-JISでは、第一バイトが 0x80~0xFF の場合は2バイト文字だと判断します。なので VSS6 は上記バイト列は以下のように見えます。
E3-81 82-E3 81-84 E3-81 86-0D 0A
このため、最後の改行文字「0D-0A (CR-LF)」が泣き別れます。(0Dを第二バイトだと誤認識する)
この結果、改行文字が「0A (LF)」だけであるように見えます。VSS6 はチェックインの際、これを自動的に補って「0D-0A (CR-LF)」にします。
E3-81 82-E3 81-84 E3-81 86-0D 0D-0A
この VSS6 にチェックインしたソースコードを、Visual Studio がリロードすると前述のダイアログが表示されます。なぜならば VSS6 によって修正されたバイト列を UTF-8 としてみると、「0D 0D-0A (CR CR-LF)」と CR 単独の改行コードがあるように見えるからです。
E3-81-82 E3-81-84 E3-81-86 0D 0D-0A
この段階で、上記ダイアログで「はい」を押すと、改行コードが標準化(=CR+LF)されるため以下のようになります。
E3-81-82 E3-81-84 E3-81-86 0D-0A 0D-0A
この結果、空行が一行増えます。
ちなみにここで、改行が無駄だからと改行を削除してしまう最初に戻ってしまうため、同じことを繰り返してしまいますので、それはしてはいけません。
これは、行末尾にある連続したマルチバイト文字が奇数バイトの場合に発生します。具体的にはコメントなどで漢字が末尾にある場合に発生します。
しかし、末尾が漢字であれば必ず発生するわけでしありません。発生しない場合は行末の連続したマルチバイト文字が偶数バイトである場合です。また、行末がシングルバイト文字の場合は発生しません。
このようなことから、「末尾にスペースをいれておくと化けない」という対策になっていたりします。
また、VSS6 で文字化けしたソースコードを一括で修正したい場合は、(OD OD-0A) を (20 0D-0A) に置き換えることで、文字化けを一掃できます。
もっとも今更 VSS6 を使うな、という話もありますが…
(*1) 別に Visual Studio 2005 でなくても 2008 でも 2010 でも再現します。たぶん…
通りすがりのVB
VSS格納時の設定として、バイナリとして保存していれば、その事象は回避できますよ。
Link | 2016年3月4日 10:39
通りすがり
バイナリで登録すると相違点表示してくれなくなるので行末にスペース追加した方が良いかなと
Link | 2023年8月21日 17:11